


1.1. Khái niệm cấu trúc dữ liệu và giải thuật, cấu trúc lưu trữ và cấu trúc dữ liệu
1.1.1. Khái niệm cấu trúc dữ liệu và giải thuật
Cấu trúc dữ liệu (Data Structure) là cách lưu trữ, tổ chức dữ liệu có thứ tự, có hệ thống để dữ liệu có thể được sử dụng một cách hiệu quả.
Giải thuật Algorithms (hay còn gọi là thuật toán) là một tập hợp hữu hạn các chỉ thị để được thực thi theo một thứ tự nào đó để thu được kết quả mong muốn. Nói chung thì giải thuật là độc lập với các ngôn ngữ lập trình, tức là một giải thuật có thể được triển khai trong nhiều ngôn ngữ lập trình khác nhau.
1.1.2. Cấu trúc dữ liệu và cấu trúc lưu trữ
Các cấu trúc dữ liệu phổ biến bao gồm các loại như mảng, danh sách liên kết, cây, đồ thị…Mỗi loại data structure có những đặc điểm riêng. Vì vậy việc hiểu và chọn cấu trúc phù hợp là rất quan trọng để đảm bảo tính hiệu quả và hiệu suất của chương trình.
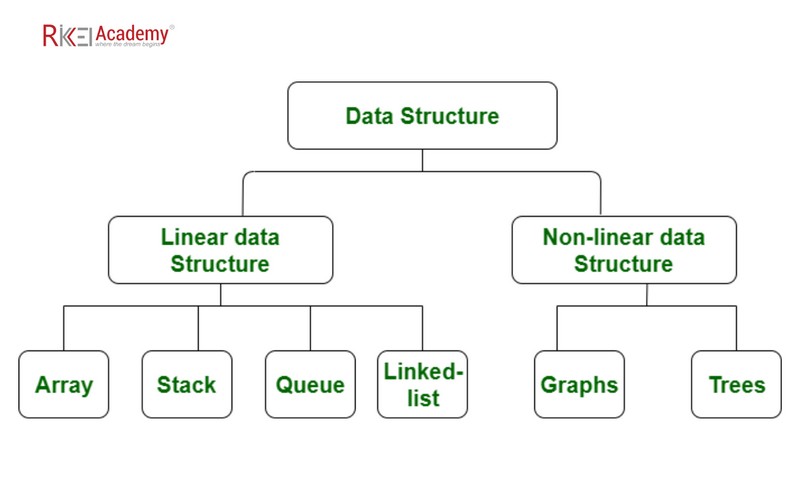
Cấu trúc dữ liệu tuyến tính là cấu trúc trong đó các phần tử dữ liệu được sắp xếp theo thứ tự tuần tự hoặc tuyến tính và mỗi phần tử được liên kết với các phần tử kế tiếp và trước đó của nó. Ví dụ về cấu trúc tuyến tính: mảng, ngăn xếp (stack), hàng đợi (queue), danh sách liên kết (linked list),…
Cấu trúc dữ liệu phi tuyến tính không có cấu trúc phân cấp rõ ràng, nghĩa là các phần tử có thể có nhiều phần tử con và/hoặc cha. Ví dụ về cấu trúc dữ liệu phi tuyến tính bao gồm cây, đồ thị,….
1.2. Cấu trúc dữ liệu
1.2.1. Các kiểu dữ liệu cơ bản
1.2.1.1 Kiểu dữ liệu số nguyên
Kiểu dữ liệu số nguyên bao gồm tất cả các số nguyên dương và số nguyên âm. Chúng ta sẽ sử dụng từ khóa int để xác định kiểu dữ liệu số nguyên. Một biến có kiểu dữ liệu int được cấp phát 4 byte bộ nhớ. Nó có thể lưu trữ bất kỳ giá trị nào trong khoảng từ −231 đến 231−1.
Ví dụ về một khai báo kiểu dữ liệu số nguyên:
int integer_number = 100;Nếu bạn lưu trữ 100.5 trong một biến có kiểu dữ liệu số nguyên, nó sẽ lưu giá trị là 100. Tức là nó sẽ tự động được cắt bớt phần thập phân.
1.2.1.2 Kiểu dữ liệu số thực
Kiểu dữ liệu float
Kiểu dữ liệu số thực chứa một số có phần thập phân. Chúng ta sẽ sử dụng từ khóa float để định nghĩa kiểu dữ liệu số thực. Một biến có kiểu dữ liệu là float được cấp phát 4 byte bộ nhớ. Nó có thể lưu trữ bất kỳ giá trị nào trong khoảng từ −231 đến 231−1.
float float_number = 10.7;Kiểu dữ liệu double
Kiểu dữ liệu double có thể chứa các giá trị có phần thập phân tương tự như float. Chúng ta sẽ sử dụng từ khóa double để định nghĩa kiểu dữ liệu double. Một biến có kiểu dữ liệu là double được cấp phát 8 byte bộ nhớ. Nó có thể lưu trữ bất kỳ giá trị nào trong khoảng từ −263 đến 263−1. Và nó được gọi là kiểu dữ liệu số thực với độ chính xác kép.
double double_number = 10.65417;1.2.1.3 Kiểu dữ liệu ký tự
Kiểu dữ liệu ký tự chứa một ký tự duy nhất từ bộ mã ASCII. Chúng ta sử dụng từ khóa char để xác định kiểu dữ liệu ký tự. Một biến kiểu char được cấp phát 1 byte bộ nhớ. Nó có thể lưu trữ bất kỳ giá trị Unicode nào trong khoảng từ −27 đến 27−1.
char character = 'b';1.2.1.4 Kiểu dữ liệu boolean
Kiểu dữ liệu boolean lưu trữ một giá trị logic. Nó có thể lưu trữ giá trị true và false. Chúng ta cũng có thể sử dụng số 1 để biểu diễn giá trị là true và 0 để biểu diễn giá trị là false. Chúng ta sử dụng từ khóa bool để định nghĩa kiểu dữ liệu boolean. Một biến kiểu dữ liệu bool được cấp phát 1 byte bộ nhớ.
bool boolean = false;1.2.1.5 Kiểu dữ liệu void
Kiểu dữ liệu void biểu diễn cho một thực thể không có chứa giá trị. Khi kiểu dữ liệu là void, không có bộ nhớ nào được cấp phát.
Được tham khảo từ website: https://tek4.vn/khoa-hoc/lap-trinh-cpp-tu-co-ban-den-nang-cao/cac-kieu-du-lieu-co-ban
1.2.2. Các kiểu dữ liệu cấu trúc
1.2.2.1 Mảng (array)
Mảng là một cấu trúc dữ liệu linear cho phép lưu trữ nhiều giá trị của cùng kiểu dữ liệu trong một biến. Thay vì cần tạo nhiều biến riêng lẻ để lưu trữ các giá trị đó, ta có thể sử dụng một mảng để lưu trữ chúng. Mảng được biểu diễn dưới dạng một danh sách các giá trị, mỗi giá trị có một vị trí riêng được gọi là chỉ số (index).
Mảng được sử dụng để lưu trữ các phần tử có độ dài cố định và không thay đổi và khi cần truy cập nhanh đến các phần tử thông qua chỉ số.

Mảng có thể được phân thành các loại khác nhau:
- Mảng một chiều
- Mảng đa chiều (gồm mảng 2 chiều)
Một số ứng dụng của mảng bao gồm:
- Lưu trữ một danh sách các phần tử dữ liệu thuộc cùng một kiểu dữ liệu
- Hỗ trợ lưu trữ phụ cho các cấu trúc khác
- Lưu trữ các phần tử dữ liệu của một cây nhị phân (binary tree) có số lượng cố định
- Lưu trữ ma trận bằng cách dùng bảng hai chiều
1.2.2.2 Kiểu dữ liệu cấu trúc [Có thực hành]
Struct là một kiểu dữ liệu có cấu trúc, được kết hợp từ các kiểu dữ liệu nguyên thuỷ do người lập trình định nghĩa để thuận tiện trong việc quản lý dữ liệu và lập trình.
Xét bài toán sau:
Ta cần lưu trữ thông tin của 10 sinh viên với mỗi sinh viên gồm có các thông tin như
- Mã số.
- Họ tên.
- Nơi sinh.
- CMND.
Khi đó, để lưu thông tin của 1 sinh viên ta cần 4 biến chứa 4 thông tin trên. Nếu muốn lưu thông tin 10 sinh viên thì cần 40 biến. Chắc không quá nhiều, nhưng nếu muốn lưu thông tin của 1000, 10000 sinh viên thì sao?
- Số lượng biến lúc này rất nhiều khiến cho code dài dòng khó thao tác, khó kiểm soát.
Từ đó người ta mới đưa ra khái niệm kiểu dữ liệu có cấu trúc để giải quyết vấn đề trên.
Ý tưởng là đóng gói các thông tin đó vào 1 đối tượng duy nhất. Như vậy thay vì phải khai báo 40 biến thì ta chỉ cần khai báo 1 mảng 10 phần tử mà mỗi phần tử có kiểu dữ liệu ta đã định nghĩa.
Đặc điểm của struct:
- Là một kiểu dữ liệu tham trị
- Dùng để đóng gói các trường dữ liệu khác nhau nhưng có liên quan đến nhau.
- Bên trong struct ngoài các biến có kiểu dữ liệu cơ bản còn có các phương thức, các struct khác.
- Muốn sử dụng phải khởi tạo cấp phát vùng nhớ cho đối tượng thông qua toán tử new.
- Struct không được phép kế thừa
1.2.3. Các kiểu dữ liệu trừu tượng
1.2.3.1 Danh sách liên kết (Linked List)
Một danh sách liên kết (Linked List) là một cấu trúc dữ liệu được sử dụng để lưu trữ một tập hợp các phần tử dữ liệu dưới dạng các nút (node). Mỗi nút chứa dữ liệu thực tế và các con trỏ (pointer) đến các nút khác trong danh sách.
Linked List được sử dụng khi cần lưu trữ các phần tử có độ dài khác nhau và cần thêm hoặc xóa phần tử một cách linh hoạt.
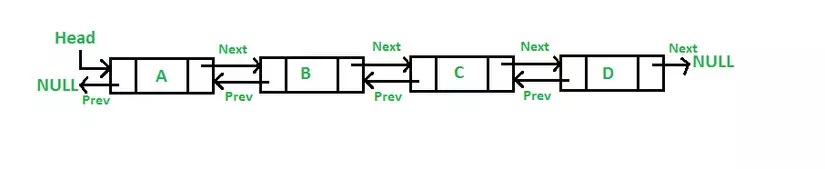
Danh sách liên kết (Linked List) có thể được phân thành các loại sau:
- Danh sách liên kết đơn (Singly Linked List)
- Danh sách liên kết kép (Doubly Linked List)
- Danh sách liên kết vòng (Circular Linked List)
Một số ứng dụng của Linked List:
- Giúp triển khai các cấu trúc khác như stack, queue, binary tree và graph có kích thước được xác định trước.
- Giúp triển khai các chức năng quản lý bộ nhớ động (dynamic memory) của hệ điều hành
- Hỗ trợ triển khai các pháp toán như đa thức
- Thực hiện tuần tự vòng của tác vụ bằng Circular Linked List. Ví dụ, các vật phẩm trong một trò chơi được thiết lập xoay vòng và xuất hiện lại khi cần thiết
- Sử dụng để triển khai các nút chuyển tiếp và quay lại trong trình duyệt web. Ví dụ, slideshow trong web.
1.2.3.2 Hàng đợi (Queue)
Hàng đợi là một cấu trúc dữ liệu tuyến tính tương tự như Stack, trong đó phần tử đầu tiên được chèn vào đầu hàng đợi và phần tử cuối cùng được chèn vào cuối hàng đợi. Nó tương tự như một hàng đợi ở quầy bán vé, người đến trước sẽ được phục vụ trước.
Queue được sử dụng khi cần quản lý các hoạt động theo kiểu FIFO và xử lý các yêu cầu một cách tuần tự.

Hàng đợi (Queue) gồm các loại sau:
- Hàng đợi đơn giản (Simple Queue)
- Hàng đợi vòng (Circular Queue)
- Hàng đợi ưu tiên (Priority Queue)
- Hàng đợi kép (Dequeue)
Một số ứng dụng của Queue:
- Dùng để tìm độ rộng của graph
- Quản lý tác vụ trên hệ điều hành, công việc trên máy tính đảm bảo các tác vụ được thực thi theo thứ tự đúng.
- Xử lý các sự kiện bất ngờ và ưu tiên cao trong ứng dụng người dùng
1.2.3.3 Ngăn xếp (Stack)
Một Stack là một cấu trúc dữ liệu tuyến tính mà theo nguyên tắc LIFO (Last In, First Out), tức là phần tử cuối cùng được thêm vào Stack sẽ được lấy ra đầu tiên. Các phép tính thêm và xóa phần tử trong Stack chỉ được thực hiện từ đầu của Stack, gọi là đỉnh của Stack.
Stack được sử dụng khi cần quản lý các hoạt động theo kiểu LIFO và xử lý các yêu cầu theo thứ tự ngược lại với hàng đợi.

Các hoạt động chính trong Stack như sau:
- Push: Thao tác để chèn một phần tử mới vào Stack.
- Pop: Thao tác để xóa hoặc xóa các phần tử từ Stack
Một số ứng dụng của Stack:
- Dùng để xác định cú pháp biểu thức.
- Dùng để đảo ngược một chuỗi (strings)
- Tìm kiếm theo chiều sâu trong đồ thị (graph) và cây (tree)
- sử dụng trong hệ thống UNDO và REDO trong các chức năng chỉnh sửa.
1.2.3.4 Đồ thị (Graph)
Đồ thị (graph) là một cấu trúc dữ liệu bao gồm các điểm và các liên kết kết nối giữa chúng. Các điểm được gọi là đỉnh hoặc nút, và các liên kết được gọi là cạnh.
Graph được sử dụng để mô hình hóa các mối quan hệ giữa các thực thể trong thế giới thực. Ví dụ, một đồ thị có thể mô tả các mối quan hệ giữa các người dùng trên mạng xã hội,..
Đồ thị (graph) được chia làm rất nhiều loại, một số loại đồ thị gồm:
- Đồ thị không hướng (Non-Directed Graph) và đồi thị có hướng (Directed Graph)
- Đồ thị liên thông (Connected Graph) và đồ thị không liên thông (Disconnected Graph)
- Đơn đồ thị (simple graph) và đa đồ thị (multigraph)
Đồ thị có nhiều ứng dụng khác nhau, một số ứng dụng gồm:
- Biểu diễn các tuyến đường và mạng lưới trong các ứng dụng vận chuyển, du lịch
- Hiển thị các tuyến đường trong GPS
- Tạo bản đồ liên kết tài liệu của các trang web
- Dùng trong các chuyển động robot và mạng nơ-ron
1.2.4. Các tiêu chuẩn đánh giá cấu trúc dữ liệu
Do tầm quan trọng đã được trình bày trong phần trước nhất thiết phải chú trọng đến việc lựa chọn một phương án tổ chức dữ liệu thích hợp cho đề án. Một cấu trúc dữ liệu tốt phải thỏa mãn các tiêu chuẩn sau :
Phản ánh đúng thực tế : Đây là tiêu chuẩn quan trọng nhất, quyết định tính đúng đắn của toàn bộ bài toán. Cần xem xét kỹ lưỡng cũng như dự trù các trạng thái biến đổi của dữ liệu trong chu trình sống để có thể chọn cấu trúc dữ liệu lưu trữ thể hiện chính xác đối tượng thực tế.
Ví dụ : Một số tình huống chọn cấu trúc lưu trữ sai :
– Chọn một biến số nguyên int để lưu trữ tiền thưởng bán hàng (được tính theo công thức tiền thưởng bán hàng = trị giá hàng * 5%), do vậy sẽ làm tròn mọi giá trị tiền thưởng gây thiệt hại cho nhân viên bán hàng. Trường hợp này phải sử dụng biến số thực để phản ánh đúng kết quả của công thức tính thực tế.
– Trong trường trung học, mỗi lớp có thể nhận tối đa 28 học sinh. Lớp hiện có 20 học sinh, mỗi tháng mỗi học sinh đóng học phí $10. Chọn một biến số nguyên unsigned char ( khả năng lưu trữ 0 – 255) để lưu trữ tổng học phí của lớp học trong tháng, nếu xảy ra trường hợp có thêm 6 học sinh được nhận vào lớp thì giá trị tổng học phí thu được là $260, vượt khỏi khả năng lưu trữ của biến đã chọn, gây ra tình trạng tràn, sai lệch.
Phù hợp với các thao tác trên đó: Tiêu chuẩn này giúp tăng tính hiệu quả của đề án: việc phát triển các thuật toán đơn giản, tự nhiên hơn; chương trình đạt hiệu quả cao hơn về tốc độ xử lý.
Ví dụ : Một tình huống chọn cấu trúc lưu trữ không phù hợp:
Cần xây dựng một chương trình soạn thảo văn bản, các thao tác xử lý thường xảy ra là chèn, xoá sửa các ký tự trên văn bản. Trong thời gian xử lý văn bản, nếu chọn cấu trúc lưu trữ văn bản trực tiếp lên tập tin thì sẽ gây khó khăn khi xây dựng các giải thuật cập nhật văn bản và làm chậm tốc độ xử lý của chương trình vì phải làm việc trên bộ nhớ ngoài. Trường hợp này nên tìm một cấu trúc dữ liệu có thể tổ chức ở bộ nhớ trong để lưu trữ văn bản suốt thời gian soạn thảo.
LƯU Ý :
Đối với mỗi ứng dụng , cần chú ý đến thao tác nào được sử dụng nhiều nhất để lựa chọn cấu trúc dữ liệu cho thích hợp.
Tiết kiệm tài nguyên hệ thống: Cấu trúc dữ liệu chỉ nên sử dụng tài nguyên hệ thống vừa đủ để đảm nhiệm được chức năng của nó.Thông thường có 2 loại tài nguyên cần lưu tâm nhất : CPU và bộ nhớ. Tiêu chuẩn này nên cân nhắc tùy vào tình huống cụ thể khi thực hiện đề án . Nếu tổ chức sử dụng đề án cần có những xử lý nhanh thì khi chọn cấu trúc dữ liệu yếu tố tiết kiệm thời gian xử lý phải đặt nặng hơn tiêu chuẩn sử dụng tối ưu bộ nhớ, và ngược lại.
Ví dụ : Một số tình huống chọn cấu trúc lưu trữ lãng phí:
– Sử dụng biến int (2 bytes) để lưu trữ một giá trị cho biết tháng hiện hành . Biết rằng tháng chỉ có thể nhận các giá trị từ 1-12, nên chỉ cần sử dụng kiểu char (1 byte) là đủ.
– Để lưu trữ danh sách học viên trong một lớp, sử dụng mảng 50 phần tử (giới hạn số học viên trong lớp tối đa là 50). Nếu số lượng học viên thật sự ít hơn 50, thì gây lãng phí. Trường hợp này cần có một cấu trúc dữ liệu linh động hơn mảng- ví dụ xâu liên kết – sẽ được bàn đến trong các chương sau.
1.2.5. Các thao tác cơ bản trên một cấu trúc dữ liệu
Các thao tác phổ biến bao gồm:
- Thêm phần tử: Thêm một phần tử mới vào cấu trúc dữ liệu.
- Xóa phần tử: Xóa một phần tử khỏi cấu trúc.
- Truy cập phần tử: Truy cập một phần tử trong cấu trúc để đọc hoặc chỉnh sửa giá trị của nó.
- Sắp xếp: Sắp xếp các phần tử theo một tiêu chí nào đó.
- Tìm kiếm: Tìm kiếm một phần tử dựa trên giá trị của nó.
- Thay đổi kích thước: Thay đổi kích thước của cấu trúc để đáp ứng nhu cầu lưu trữ dữ liệu.
1.3. Giải thuật và đánh giá độ phức tạp của giải thuật
1.3.1. Giải thuật
Trong khi giải một bài toán chúng ta có thể có một số giải thuật khác nhau, vấn đề là cần phải đánh giá các giải thuật đó để lựa chọn một giải thuật tốt nhất.
2. Phân tích lý thuyết
Có thể coi đây là phân tích chỉ dựa trên lý thuyết. Hiệu quả của giải thuật được đánh giá bằng việc giả sử rằng tất cả các yếu tố khác (ví dụ: tốc độ vi xử lý, …) là hằng số và không ảnh hưởng tới sự triển khai giải thuật.
3. Phân tích tiệm cận:
Việc phân tích giải thuật này được tiến hành sau khi đã tiến hành trên một ngôn ngữ lập trình nào đó.
Sau khi chạy và kiểm tra đo lường các thông số liên quan thì hiệu quả của giải thuật dựa trên các thông số như thời gian chạy, thời gian thực thi, lượng bộ nhớ cần dùng, …
1.3.2. Biểu diễn giải thuật
1.3.2.1. Bằng ngôn ngữ tự nhiên
Thiết kế giải thuật bằng ngôn ngữ viết là liệt kê tuần tự các bước bằng ngôn ngữ tự nhiên để biểu diễn thuật toán.
Ưu điểm:
Đơn giản, không cần kiến thức về cách biểu diễn (mã giả, lưu đồ,…)
Nhược điểm:
- Dài dòng, không có cấu trúc.
- Đôi lúc khó hiểu và không biểu diễn được thuật toán.
Ví dụ: Dùng ngôn ngữ viết để tìm ra 3 số lớn nhất trong a, b, c
- Bước 1: Gán max = a.
- Bước 2: Nếu b > max thì gán max = b.
- Bước 3: Nếu c > max thì max chính là c.
1.3.2.2. Bằng lưu đồ giải thuật
Lưu đồ bao gồm:
- Điểm bắt đầu và điểm kết thúc.
- Thao tác nhập/xuất dữ liệu.
- Thao tác xử lý.
- Điều khiển rẽ nhánh.
- Đường tiến trình.
- Chú thích.
- Ký hiệu kết nối cùng trang hay sang trang khác.


Lưu đồ
Ưu điểm:
Trực quan, dễ hình dung.
Nhược điểm:
Cồng kềnh nếu vấn đề xử lý quá phức tạp.
1.3.2.3. Bằng ngôn ngữ diễn đạt giải thuật (mã giả)
3. Mã giả
Ngôn ngữ của mã giả khá giống ngôn ngữ lập trình. Nó thường dùng cấu trúc chuẩn hóa, chẳng hạn tựa Pascal, C. Nó cũng sử dụng các ký hiệu toán học, biến, hàm.

Một mã giả
Ưu điểm:
Không cồng kềnh như lưu đồ khối
Nhược điểm:
Không trực quan bằng lưu đồ khối
1.3.4. Đánh giá độ phức tạp của giải thuật
1.3.4.1. Độ phức tạp của giải thuật là gì?
Độ phức tạp giải thuật là một hàm ước lượng (có thể không chính xác) số phép tính mà giải thuật cần thực hiện (từ đó dễ dàng suy ra thời gian thực hiện của giải thuật) đối với bộ dữ liệu đầu vào (Input) có kích thước n.
Trong đó, n có thể là số phần tử của mảng trong trường hợp bài toán sắp xếp hoặc tìm kiếm, hoặc có thể là độ lớn của số trong bài toán kiểm tra số nguyên tố, …
Giả sử X là một giải thuật và n là kích cỡ của dữ liệu đầu vào. Thời gian và lượng bộ nhớ được sử dụng bởi giải thuật X là hai nhân tố chính quyết định hiệu quả của giải thuật X:
- Nhân tố thời gian: Thời gian được đánh giá bằng việc tính số phép tính chính (chẳng hạn như các phép so sánh trong thuật toán sắp xếp).

Các phép so sánh trong thuật toán sắp xếp
- Nhân tố bộ nhớ: Lượng bộ nhớ được đánh giá bằng việc tính lượng bộ nhớ tối đa mà giải thuật cần sử dụng.
Độ phức tạp của một giải thuật (một hàm f(n)) cung cấp mối quan hệ giữa thời gian chạy và/hoặc lượng bộ nhớ cần được sử dụng bởi giải thuật.
1.3.4.2. Độ phức tạp bộ nhớ trong phân tích giải thuật (Space complexity)
Nhân tố bộ nhớ của một giải thuật biểu diễn lượng bộ nhớ mà một giải thuật cần dùng trong vòng đời của giải thuật.
Lượng bộ nhớ (giả sử gọi là S(P)) mà một giải thuật cần sử dụng là tổng của hai thành phần sau:
- Phần cố định (giả sử gọi là C) là lượng bộ nhớ cần thiết để lưu giữ dữ liệu và các biến nào đó (phần này độc lập với kích cỡ của vấn đề). Ví dụ: các biến và các hằng đơn giản, …
- Phần biến đổi (giả sử gọi là SP(I)) là lượng bộ nhớ cần thiết bởi các biến, có kích cỡ phụ thuộc vào kích cỡ của vấn đề. Ví dụ: cấp phát bộ nhớ động, cấp phát bộ nhớ đệ qui, …
Từ trên, ta sẽ có S(P) = C + SP(I). Bạn theo dõi ví dụ đơn giản sau:

Ở đây chúng ta có ba biến A, B và C và một hằng số. Do đó: S(P) = 1+3.
Bây giờ, lượng bộ nhớ sẽ phụ thuộc vào kiểu dữ liệu của các biến và hằng đã cho và sẽ bằng tích của tổng trên với bộ nhớ cho kiểu dữ liệu tương ứng.
1.3.4.3. Độ phức tạp thời gian trong phân tích giải thuật (Time Complexity)
Nhân tố thời gian của một giải thuật biểu diễn lượng thời gian chạy cần thiết từ khi bắt đầu cho đến khi kết thúc một giải thuật.
Thời gian yêu cầu có thể được biểu diễn bởi một hàm T(n), trong đó T(n) có thể được đánh giá như là số các bước.
Ví dụ, phép cộng hai số nguyên n-bit sẽ có n bước. Do đó, tổng thời gian tính toán sẽ là T(n) = c*n
Trong đó c là thời gian để thực hiện phép cộng hai bit. Ở đây, chúng ta xem xét hàm T(n) tăng tuyến tính khi kích cỡ dữ liệu đầu vào tăng lên.
1.4 Thực hành
Link: https://docs.google.com/document/d/11lKThqU6L1JMRgQiGKYR3j3NggeV3um4EI8GxKb-wvU/edit?usp=sharing